Java的执行过程
Java的执行过程
Java的执行过程
Java的执行过程整体可以分为两个部分:
第一步由javac将源码编译成字节码(Bytecode),在这个过程中会进行词法分析、语法分析、语义分析,编译原理中这部分的编译称为前端编译。
接下来无需编译直接逐条将字节码解释执行,在解释执行的过程中,虚拟机同时对程序运行的信息进行收集,在这些信息的基础上,编译器会逐渐发挥作用,它会进行后端编译——把字节码编译成机器码,但不是所有的代码都会被编译,只有被JVM认定为的热点代码,才可能被编译。
怎么样才会被认为是**热点代码呢?JVM中会设置一个阈值**,当方法或者代码块的在一定时间内的调用次数超过这个阈值时就会被编译,存入codeCache中。当下次执行时,再遇到这段代码,就会从codeCache中读取机器码,直接执行,以此来提升程序运行的性能。整体的执行过程大致如下图所示:
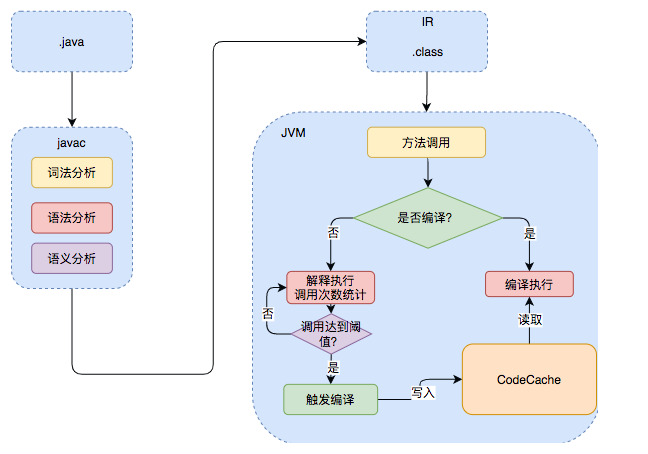
JVM 会动态决定解释执行还是 JIT 编译。(Java 程序后期越跑越快的原因)
JIT-即时编译
(Just in Time Compilation)
Java虚拟机根据方法的调用次数以及循环回边的执行次数来触发即时编译。循环回边是一个控制流图中的概念,程序中可以简单理解为往回跳转的指令,比如下面这段代码:
循环回边
1 | |
上面这段代码经过编译生成下面的字节码。其中,偏移量为18的字节码将往回跳至偏移量为4的字节码中。在解释执行时,每当运行一次该指令,Java虚拟机便会将该方法的循环回边计数器加1。
字节码
1 | |
在即时编译过程中,编译器会识别循环的头部和尾部。上面这段字节码中,循环体的头部和尾部分别为偏移量为11的字节码和偏移量为15的字节码。编译器将在循环体结尾增加循环回边计数器的代码,来对循环进行计数。
当方法的调用次数和循环回边的次数的和,超过由参数-XX:CompileThreshold指定的阈值时(使用C1时,默认值为1500;使用C2时,默认值为10000),就会触发即时编译。
开启分层编译的情况下,-XX:CompileThreshold参数设置的阈值将会失效,触发编译会由以下的条件来判断:
- 方法调用次数大于由参数-XX:TierXInvocationThreshold指定的阈值乘以系数。
- 方法调用次数大于由参数-XX:TierXMINInvocationThreshold指定的阈值乘以系数,并且方法调用次数和循环回边次数之和大于由参数-XX:TierXCompileThreshold指定的阈值乘以系数时。
分层编译触发条件公式
1 | |
上述满足其中一个条件就会触发即时编译,并且JVM会根据当前的编译方法数以及编译线程数动态调整系数s。
编译优化
即时编译器会对正在运行的服务进行一系列的优化,包括字节码解析过程中的分析,根据编译过程中代码的一些中间形式来做局部优化,还会根据程序依赖图进行全局优化,最后才会生成机器码。
1.中间表达形式(Intermediate Representation)IR
在编译原理中,通常把编译器分为前端和后端,前端编译经过词法分析、语法分析、语义分析生成中间表达形式(Intermediate Representation,以下称为IR),后端会对IR进行优化,生成目标代码。
Java字节码就是一种IR,但是字节码的结构复杂,字节码这样代码形式的IR也不适合做全局的分析优化。现代编译器一般采用图结构的IR,静态单赋值(Static Single Assignment,SSA)IR是目前比较常用的一种。这种IR的特点是每个变量只能被赋值一次,而且只有当变量被赋值之后才能使用。
SSA IR
1 | |
上述代码中我们可以轻易地发现a = 1的赋值是冗余的,但是编译器不能。传统的编译器需要借助数据流分析,从后至前依次确认哪些变量的值被覆盖掉。不过,如果借助了SSA IR,编译器则可以很容易识别冗余赋值。
上面代码的SSA IR形式的伪代码可以表示为:
SSA IR
1 | |
由于SSA IR中每个变量只能赋值一次,所以代码中的a在SSA IR中会分成a_1、a_2两个变量来赋值,这样编译器就可以很容易通过扫描这些变量来发现a_1的赋值后并没有使用,赋值是冗余的。
2.方法内联
方法内联,是指在编译过程中遇到方法调用时,将目标方法的方法体纳入编译范围之中,并取代原方法调用的优化手段。JIT大部分的优化都是在内联的基础上进行的,方法内联是即时编译器中非常重要的一环。
3. 逃逸分析
逃逸分析是“一种确定指针动态范围的静态分析,它可以分析在程序的哪些地方可以访问到指针”。Java虚拟机的即时编译器会对新建的对象进行逃逸分析,判断对象是否逃逸出线程或者方法。
逃逸分析通常是在方法内联的基础上进行的,即时编译器可以根据逃逸分析的结果进行诸如锁消除、栈上分配以及标量替换的优化。
4. Loop Transformations
C2编译器在构建Ideal Graph后会进行很多的全局优化,其中就包括对循环的转换,最重要的两种转换就是循环展开和循环分离。
5. 窥孔优化与寄存器分配
窥孔优化是优化的最后一步,这之后就会程序就会转换成机器码,窥孔优化就是将编译器所生成的中间代码(或目标代码)中相邻指令,将其中的某些组合替换为效率更高的指令组,常见的比如强度削减、常数合并等,看下面这个例子就是一个强度削减的例子:
强度削减
1 | |